Hummingbird kills Long Tail Search & Gibberish is next
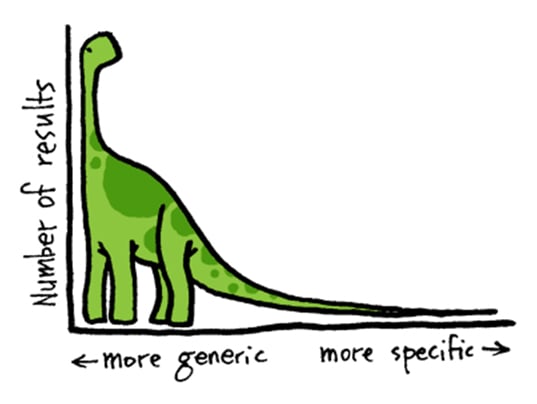
Long tail search queries supposedly make up anything up to 50% of all web searches; with 20% of searches being classed (by Google) as extremely long tail.
August’s Hummingbird update is claimed by Google to further increase their ability to refine longer tail queries through a greater understanding of content and context.
Why is Google doing this?
Google’s ultimate aim is obviously to serve more contextual ads, to an increased proportion of these long tail search queries and in the process make Google even more money via their overwhelming dominant revenue earners – AdWords & AdSense.
Data Q3 2013 via Moz
From a marketers perspective it remains tricky to target long tail as no search volume data is provided, while Google themselves often struggle to delivery ads that are relevant extreme long tail search queries.
We have seen Google get more advanced with Hummingbirds infrastructural improvements, which have increased Google’s text processing as well as content and context understanding mechanisms. This would suggest that Google intend to go down a route which places less reliance on Meta data and more emphasis on valuable content.
For example, if I had 2 search queries, A:‘best night life east London’ & B: ‘where to party Old Street London’. In theory Hummingbird will make Google more proficient at returning a page which lists London’s best clubs by locality, whilst realising that access between the two locations is straightforward and serves a page which do not necessarily target the keyword terms ‘where to party’ or ‘old street’ in the page title or html tags. Instead Google’s improved understanding of the page, enables them to understand that a particular page could be served for both search queries A & B without the keyword indicator necessarily present.
This will create obstacles for SEO’s with significant long tail traffic, on top of our much loved (not provided) keyword term, which greatly inhabits our ability to (a) see what people are searching for, (b) knowing what is driving traffic and (c) subsequently improvement content as a result of (a) & (b).
This would ultimately loop back to ‘quality content over quantity of content’, but specifically content that satisfies multiple search queries. Such content would be especially important for brands with modest social influence, link profiles and user browsing (e.g high bounce rates). However with updates to SEO best practise always come a few high profile causalities alone the way, think JC Penny’s black hat rumbling in 2010.
Beyond Hummingbird…
Google’s long run stance on quantity vs. quality would appear to be further backed up by the recent patenting of a score for demoting gibberish content – think page rank before it became largely obsolete.
Any scoring system is likely to seek content which is keyword rich, but adds little value as a page, content that has been scraped, spliced or crudely translated.
However the usual time lag associated with Google’s patenting process gives SEO’s as well as mediocre to poor Textbroker writers’ ample time to get their houses in order.
